I am assuming that you are building your first website for all users across the world. Maybe you are building it, for education/business/marketing whatever it is, but once done, you need to see users come to your application and surf the content. To attract common users, your simple domain name is not enough to encourage users to surf your application, after all, it is not Google, Facebook, Microsoft, Apple, etc. We need to depend on their service to bring our application to the common user's eye.
We need to enable few features and maintain few principles to add our application under search engine’s index. Now depending upon the parameters, token, keywords the index rank will go up and down. Let’s see how we can do it step by step.
Step 1: Configure your sitemap.xml file and robots.txt file
You can include all your external public access URLs to your sitemap.xml file so that search engines can understand the existence of that page and can crawl the page. You can create it from here as well. It should have the following structure like below -
robots.txt file is also very important to configure. It tells search engine bot which page to crawl and which are not. Using that you can restrict to crawl of a certain directory of your website.
Deep links mean, URLs with #, like www.your-site.com/#/home. Those are hard to get indexed. So, while creating routing, try to use a simple path for your page. And do the following change in your routing module.
Please go through the link and description to add a meta tag in your application. Also, you can use angular provided Meta service as well to add/update/delete meta tags. like below -
And common tags can be added to index.html page as well.
<meta property="og:type" content="article">
<meta name="robots" content="index, follow">
Also, you can add your site-verification id to your HTML. In my case, Google was my site verification provider, so I have added the following line as well.
Note: Setting up proper meta tags on your page will help google show the title, URL, and description of your page correctly in its search result.
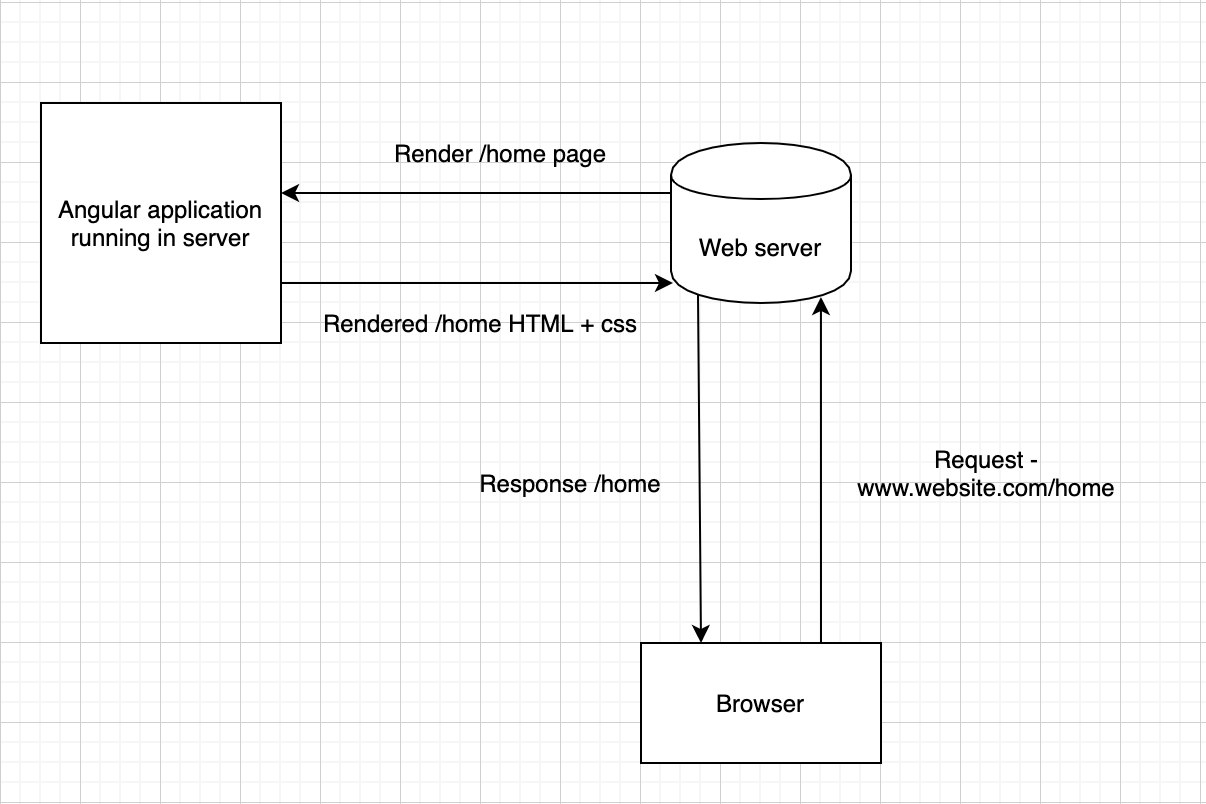
Step 7: Server-side rendering Using Angular Universal
As angular is a client-side application and it requires downloading the application bundle to load the DOM, and the search engine crawler will not be able to find the content as those are not loaded yet. To overcome this problem, serving the application in a server-rendered form. Angular Universal is the best to use it.
Why use Angular Universal?
If your application is targeting on Google Search engine, then it might not need, as google search crawl the javascript. But other search engines and social sites will be required server-side rendering to crawl your page for indexing.
Migrating an existing angular Application to a Universal Angular application:
1. Install the following node module
ng add @nguniversal/express-engine(It will update all your code automatically.)
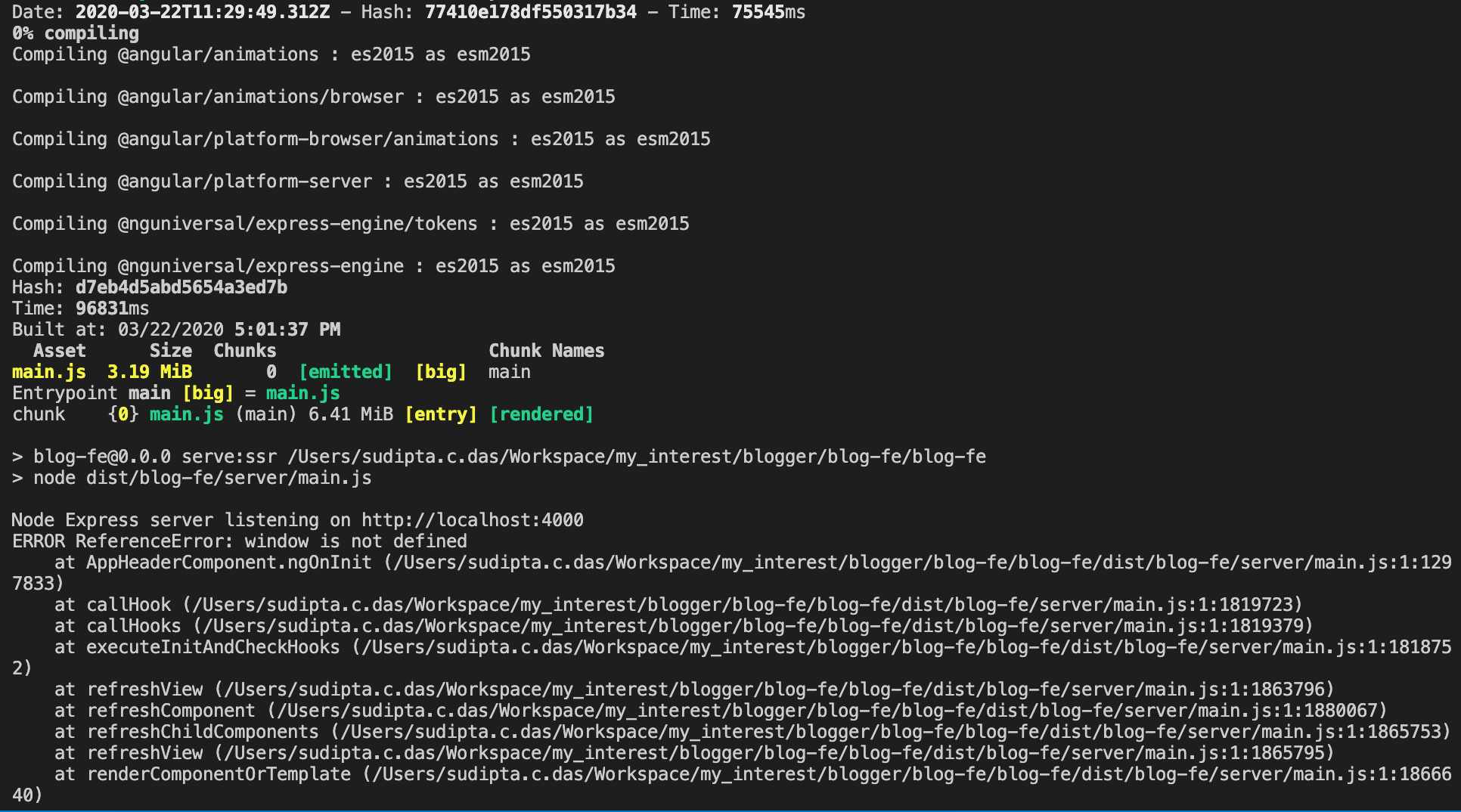
2. Once the installation is done, please run the following command to serve your application in http://localhost:4000
npm run build:ssr && npm run serve:ssr
During this command, you might get the following error -
Node Express server listening on http://localhost:4000
ERROR ReferenceError: window is not defined
To solve this error, you need to modify few code in server.ts file - (A complete server.ts file, you can copy entire one)
import 'zone.js/dist/zone-node';
import 'reflect-metadata';
import { enableProdMode } from '@angular/core';
import { ngExpressEngine } from '@nguniversal/express-engine';
import * as express from 'express';
import * as cors from 'cors';
import * as bodyParser from 'body-parser';
import { join } from 'path';
import expressStaticGzip from 'express-static-gzip';
import { AppServerModule } from './src/main.server';
Step 9: Last but not least, you can leverage Google search API to crawl your page.
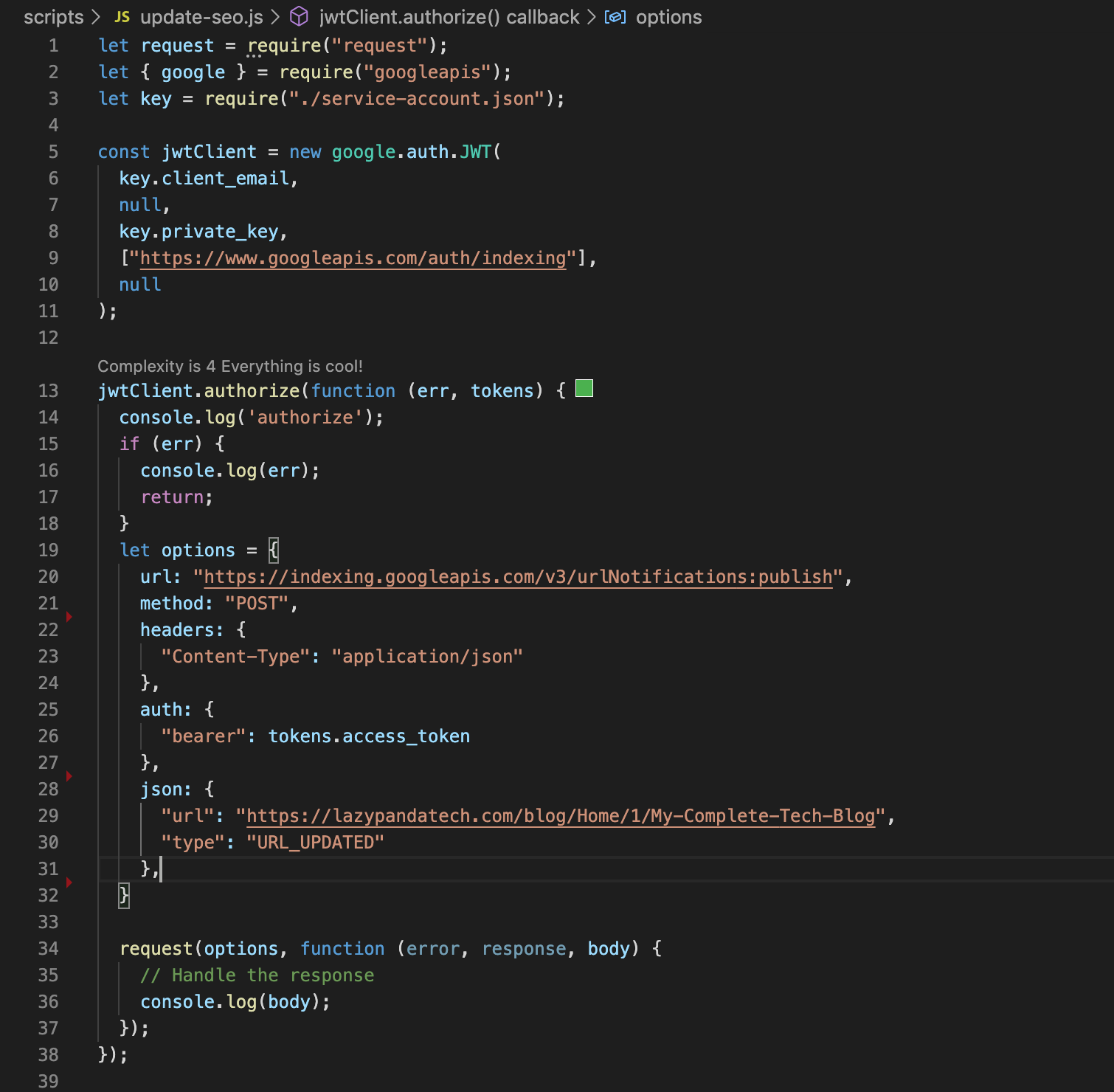
Google search API is another way to make sure your page will be crawled in the next 48 hours (probably). To use the Google search API you need to create one service account followed by enabling Search API too. The complete documentation is here. You can use the automated API console to submit your endpoint, but I would suggest creating one service account adding yourself as an owner, and writing a simple node js application to submit your endpoints.
The nodejs script which I have used to submit my endpoints is like this below -
Hope you enjoyed the article if you have any other suggestions please comments below.
Loading comments...